��ȥ��“�˵���”ռ���Ǽݼ������л���Ȩ��ͬ����������������VLA��Vision-Language-Action���������������ҡ�Ʒ�Ƹ߹ܡ�ר�ҡ�������“��P”�Ƿ��³�����ǰҵ���Ǽݾ���������ͨ����Ʒ˵���������۵�ֱ����ײ���١����ڣ���Ҷ�����VLA�ܷ������L3��L4�Ǽݣ��������жϷ��硣
������Ȼ����������Ȩ�����ᣬ����ҲҪ�������г��϶��֡�9�·ݣ���Ϊ�����û�ȫ������Ǭ���Ǽ�ADS 4��С��Ҳ����9����������VLA���ټ��ϸոշ���VLAϵͳ��Ԫ�����У��Լ�����“����”VLA��Ʒ�����룬8�·�VLA����𱬣��ٺ���������
�����µ��Ǽ���Ӫ�γ�
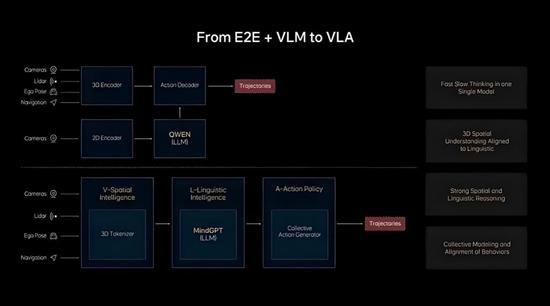
��������ʲô��VLA��������˼������“�Ӿ�-����-��Ϊ”����Ҳ�Ǹ���ģ�͡�ʵ���Ͼ��ǽ��Ӿ���Ϣ��Ϊ���룬��һ����ģ����ο���������Ĵ�ģ�͵�ָLLM�����⿴��ȥ�ƺ���ģ��������ķ�ʽ�������ϣ�VLA����ͽҲ����������˼ά����Ϊģʽ����Ѱ����С�
��������VLA���IJ���ʶ��ͼ��ͼ�����⣬����������ı���Token���������ģ�ͣ���ģ������ʻ���飻���������ɹ켣+�������������顣
����8��8����������˴���ϣ������ˣ������Ƽ�CEO����ʾ��“VLA�����ɵ��ʽ�ļܹ�”�������˻���ʾ��VLA�����������������ݣ���Ӧ�Բ�������Ԥ����ͻ��“�ٽ��”�������Ǽ��ϣ�������ֱ��L4����
����VLA��Щ�̰壬С�������롢Ԫ�����еȼ��VLA·�ߵ���ҵ��������ᣬ�����ǵ�C�˿��ܵķ�Ӧ���ⲻ����Щ��ˬ�������dz�����������VLA�����롣
����������߸�����������“����”����Ϊ��BU CEO����־�ֹ�����ʾ����Ϊ������VLA·�ߡ�“VLA����ȡ�ɣ�����������������

�������Զ���ʻ��·�������Ǹ�����WA��World Action������Ϊģ�ͣ���ʡ����”����“����”��
�����ⷬ�۵���“��”��ֱ�ӷ���VLA�������ӣ���Ӫ���ݱ�÷�����VLA+RL��ǿ��ѧϰ��VS�������棨�ƶˣ�+������Ϊģ�ͣ����ˣ�������Ϊǣͷ��
����VLA�����ƺͶ̰�
���������˻���˵��һ�㣬�Ǿ��dz�˼ά����VLA���������˷�Ӧ���뼶�ģ�ֻ�ʺϷ�ʱ���������粴��������˼ά��������3��4�㣩��������β��������������ǿ������Ȼ�����졣�����Ŷ��������Ϊ“����ϵͳ”���ò�����˼ά���Ķ˵���ϵͳ����Խṹ�Գ���������“������”��ʻ����VLAģ�ͣ����Ż�Ϊ���ⶨ�Ƶ�˼ά����VLA����Ϊ�����Կ�����ʱ��Ҳ����“����ϵͳ”��
�������“���ⶨ��”�������̷�Ӧʱ���أ�����С�ʱ���Token�����٣������н��롢��������Ȼ����ΪTokenһ���������
����������ˣ�VLA�ڳ�β�����еķ�Ӧ�ٶ���Ȼ���ɡ���Ӧ�ٶ�Ҳ�ã�����ģ�ʹ�СҲ�ã����ܵ������������ڴ������������Լ��Waymo��L4��ʱ���൱�ֱ����ں�����ֱ������A100������FP32����������ֵ19.5TFlops������1.6TB/s�����������������ԣ�A100����������δ��̫��Ӣΰ���Thor��FP4ϡ��������ֵ2070TFlops���൱��A100������1%���ٴ���Ʊ֮��������������Ҫ�Լ���������������ǿ���εС����С������������оƬ��Ŀ��

��������Ϊ�����Է�����һ���ڣ����˽��俴��“����ʽ”�˵��ˡ���һЩ���ӳ����У����缫���ڵ��������ٵ�ǰ�����ͳ����Ա�����Ұ�����ơ����ʱ�����������Ļ��������ᳫ�����Լ�ʻ�������Կ���ȷ���������ڵ����������ͷ�۵ij�ϫ��������ʱ�����������ⳡ����VLA���ֵúܺá�������һЩ�������Ӿ����Դ�ģ�ͷ������ܳ��ֳ�ʶ�Դ���������Դ�ģ�͵Ļþ����һ�ޡ����Ƕ�μ�������ģ��Ϊ���������ϧα�����ݺ���������Ȼ����������֪��ʲô��“α��”��ֻ��Ԥ��Token����ƫ����ѡ�
����Ҳ���˳ƣ�3Dת2D��������3D��˹���䣬һ�ֽ�ʵʱ��������ת��Ϊ��˹�ֲ�����ѧ�����������У������������ܺܺ��������г����������ۿ����ĺܶ�ϸ����ر��ǵ��������壬�������൱�����ģ�����Զ��ֻռ2�����ص�Ͱ������������ڣ�99%����½����������ȫ�����ġ�
������ˣ�VLA���ٵ����⣬���Լ�Ϊ��������������Ч�����⣨˼��̫�ã���
��������ģ�ͣ�����ȥ����
������“����ģ����”��Ϊ����������ģ�ͣ����Ա�������������������ݡ������ϣ�����ģ�ͣ�������ѧ��ʽģ����ʵ�������硣�����Ǽ������ڣ�World Model����world�˸�ɶ�����������顣
����3D��˹��Ȼ����������3D��˹���������˵��λ����Ϣ���������˵����ڿռ���״���ֲ�����С����Э��������Լ���ɫ�����ȡ���Щ�������������߱�����ģ�͵ı�����ͬ�����������ģ�͵���ҵ������Ҳƫ�������״��Ҳ��Ϊʲô���ǿ��������Ӿ��뼤���״��ӵ����Ҳ�е��Ʋ�������ζ����
������������ģ���ܹ��������ݣ�������˵������Ȼ�������Ԥѵ���ͷ��棬��������ģ�Ϳ���ʵ�ֶ˲���������ʱ����ν����������������������Ԥ��δ�������������������ʵ�������ϵúܽ�����ôҲ��ζ�ſ���Ԥ����������δ���ļ����ӡ�

���������ϣ�����ģ��ӵ�ж�������õ���������˼��Ҳ�ܿ죨��Ϊû������������һ����������־��Ϊ������ģ�ͽ���Ϣ�����������Ӿ���Ϣ������ģ�ͣ�����ֱ�������Ϊָ��س�������ȥ��������
�������ǣ���Ȼ����ģ�Ͷ���ʵ��β������û̫��Ҫ����Ȼ���������ݽ���ѵ�������Զ�����������Ҫ�������Щ����������������ƫ���������Щ��ȱ�����ݣ�ѵ��������ϵͳ�����ܴ������Թ�����������ͬʱ������ģ�Ͳ���VLA���������߹��̿ɼ��������⡣�������⣬ֻ�ܻ��ݵ�ѵ��֮ǰ��
������ͬ���ʾ�������
��������˫��������Լ���·�����ߵ�L4��VLA����ս���ڣ������“����”�������ӿռ以��������������ޣ����ܲ��������⡣������ģ������ͼ����ռ���֪�������������⣬��������ģ��֮�ͺ��ѿ���ѵ�����������ּ�����������������λ��Ž��أ���ǰ�����������ڡ�
������occ��BEV��ͬ����һ��ѧ����Ҳû�����VLA������ģ�͵�DZ������ѧ���绹û������£����̽�Ϳ�ʼ�����ҵ���ˡ������ȶ��֣������ǵȼ�������֧�����ƣ�������ǰ�Ǽݵľ����Ѿ���ʼѹ���������ˡ�������������������֣����ܾ�“û�̿ɴ�”����ζ����ҵ�����ɥʧ��
�����������Ƶ�����������ģ�����ͷ���Ǽݵľ�����������ʽ�ת�Ƶ�VLA������ģ��“·�߶���”���������ǵ�һЩ���̣���û�㶨���·�ߣ�����������ͬһ���г�������Ҳ������һ��ά�ȵľ����ˡ�������������“��е��ս��”��“������ɱ”���档˵ʵ��������3�꣬������������������ʵ������˵�ħ�á�

�������գ�����·�������ȳɹ���ȡ���ڼ���ƿ����ͻ���ٶȡ������ɱ����»������Լ����ģ·�ⷴ���ĵ���Ч�ʣ�ʱ�����������յĴ𰸡���Ѱ��Խ��L2����Ĺ����У���������Ǯ���ʣ��ܷ��������鵽��������ˮƽ���Ǽݣ��в�ȷ����
������������վ���ش��Ľ�������Ϣ������������ζ����ͬ��۵㼰�����������е���Ȩ��Ϊ���������Ρ����漰��Ȩ�����⣬����������ϵ����ϵQQ��26887486�������ǽ���ʱɾ��������
�������ӣ�https://www.yunlianauto.com/article/53/52482.html